发布时间:2018-11-7 阅读量:989 来源: 我爱方案网 作者: Jude编辑
边缘计算出现的背景
big data is like teenage sex;
everyone talks about it
nobody really knows how to do it
everyone thinks everyone else it doing it,
so everyone claims they are doing it…
这些海量的数据被不断生产出来,然后不同的公司、开发者再经过或简单或复杂的过程将数据搬运到公有云的数据仓库之中,接下来,这些公司和开发者则使用云服务商——亚马逊、微软、阿里云、Google——提供的各种数据分析、挖掘工具,从中找出「insight」。
在 CBinsights 的数据库里,2019 年全球 IoT 市场预计达到 17000 亿美元,这个巨大的市场规模也意味着将有海量的数据需要处理,也进一步刺激了云计算公司的发展,下图是关于云计算的新闻热度。
更进一步,云计算公司,尤其是主打公有云的公司,也进入到发展的快车道,下图是美国三大公有云公司过去两年客户增长状况。
但随着数据量的继续增加以及数据处理多样化的要求,基于云端的大数据处理面临诸多挑战。
类似这样的数据处理需求正在变得越来越多,比如普通人类个体每天产生的数据量也以惊人的速度增长。预计到 2020 年,普通人每天平均产生 1.5GB 的数据,这些数据可能来自于智能手表、手环收集的运动数据,也可能来自智能手机收集的交通数据以及你浏览网页、社交媒体等产生的 Cookie 数据等等。
边缘计算的优势
这两个概念有容易混淆。「雾计算」更强调在设备的网关里处理数据,数据被「雾计算」收集到设备的网关,进而处理、存储,并将处理后的数据发挥需要数据的设备中。
这也意味着,边缘计算有着诸多「先天优势」,其一,更实时、更快速的数据处理能力。由于减少了中间传输的过程,数据处理的速度也更快。
其三,更低的网络带宽需求。随着联网设备的增多,网络传输压力会越来越大,而边缘计算的过程中,与云端服务器的数据交换并不多,因此也不需要占用太多网络带宽;
第五,边缘计算让数据隐私保护变得更具操作性,这在今年 5 月欧盟通过史上最严格的数据保护法律之后意义重大。由于数据的收集和计算都是基于本地,数据也不再被传输到云端,因此重要的敏感信息可以不经过网络传输,能够有效避免传输过程中的泄漏。
下图里,你会发现边缘计算的新闻关注度从 2017 年开始变得越来越高。
边缘计算的几个重要玩家也是公有云的巨头,亚马逊、微软、Google 先后有自己的布局。

……微软的野心是希望通过构建一个「云—端」的协同产品通道,将人工智能的各项能力输出到各个产品中,比如今年的主旨就是边缘计算。
为此,微软在边缘计算领域持续发力。开源了 Azure IoT Edge Runtime,这是一个连接云和物联网设备的开发框架。开发者通过这个框架可以直接在设备端开发拥有机器学习能力的应用,比如第一批合作伙伴里的大疆,就利用这个框架实现无人机本地的图像识别功能。
同时,微软还将高通拉入自己的阵营,合作的主旨也是视觉领域的边缘计算,快速构建移动终端设备上的图像处理能力……
Cloud IoT Edge extends Google Cloud’s powerful data processing and machine learning to billions of edge devices, such as robotic arms, wind turbines, and oil rigs, so they can act on the data from their sensors in real time and predict outcomes locally……
除此之外,还有很多科技巨头加入到边缘计算的赛场。比如惠普企业(Hewlett Packard Enterprise)就表示将在未来四年投资 40 亿美元用于边缘计算。惠普企业的边缘计算产品名叫「Edgeline Converged Edge Systems」,其主要客户群体是工业领域,比如油田、煤矿等,这些特定行业的工作环境里,无法满足云端数据的处理条件,因此边缘计算就成为一个重要需求。
战略层面,胡晓明提了一个「小目标」,阿里云计划在未来 5 年内连接 100 亿台设备。而在战术上,阿里希望「打通云、边、端,整合包括物联网操作系统 AliOS Things、IoT 边缘计算产品、通用物联网平台,实现物的实时决策和自主协作。」

微软 CTO Kevin Scott 曾坦言,边缘计算还处在相对早期阶段。但透过这段时间内的场景落地状况,我们也可能窥见边缘计算的潜力。

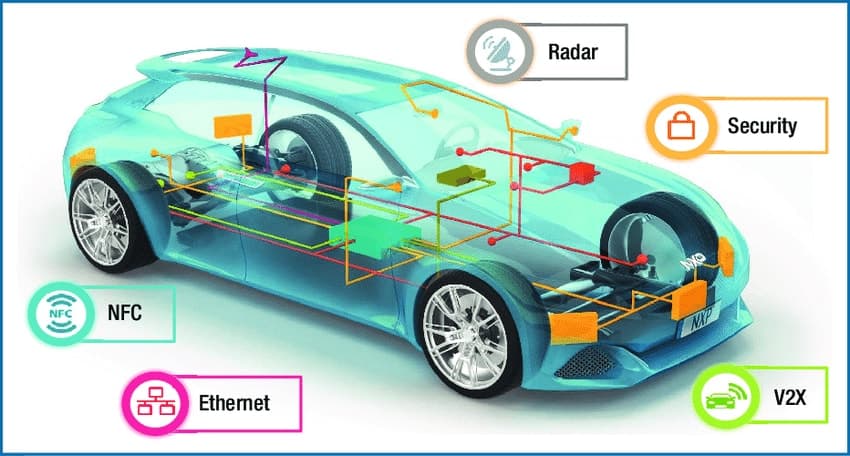
在国内,不管是阿里旗下的斑马网络还是百度的小度车载,都在将汽车变成一种「移动的数据中心」,只是相对于自动驾驶,联网汽车的数据量和处理要求要简单很多。即便如此,由于汽车的数据处理不能出现任何的卡顿和延迟,这也就需要在汽车里部署数据处理能力。
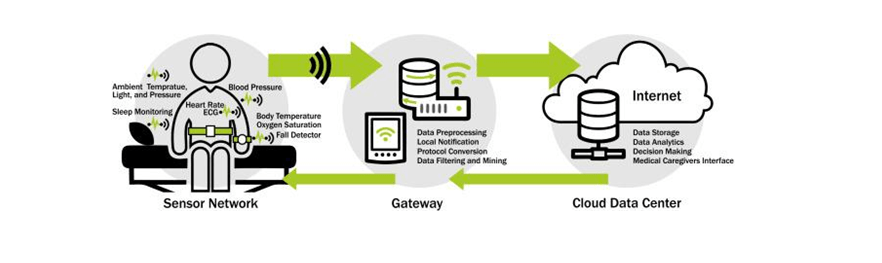
随着苹果发布 Apple Watch 所带来的新穿戴设备潮流,这些边缘设备也终于开始拥有了自己的芯片,并能实现一些简单的计算。医生也可以通过这些计算结果作出一些简单诊断。
以流程型生产为例,一条生产线其实就是数据流动的通道,产品从上一名工人传递到下一个工人,同时伴随着产品数据的传递。在这个过程中,如果由于某一名工人错误操作的导致了数据异常,在下一名工人开始操作时,基于边缘计算的生产线可以做出预警提示。如果再进一步,当机器学习能力被边缘计算融入到生产线的时候,工人的不合规操作可以被实时监测出来并预警,这对提升产品的良品率意义重大。
前面谈了这么多边缘计算的优势和应用场景,并不是要证明边缘计算可以替代云计算,两者没有谁好谁坏,更应该具体到不同设备、不同应用以及不同场景里,看看到底谁更合适。
这便是一个典型需要边缘计算的场景,而当 2017 年,包括华为、苹果都在新一代智能手机芯片中加入 NPU(神经网络处理单元)之后,也赋予了智能手机全新的边缘计算处理能力,华为 P20 Pro 的逆天夜拍效果,除了硬件堆积之外,处理器的 NPU 也发挥了不小的作用,去年苹果推动的 AR 应用(游戏)开发热潮,其底层的技术支撑就是 iPhone 拥有了可以在边缘处理实时、海量数据的能力。
作者:<span style="color:#191919;font-family:" font-size:16px;white-space:normal;background-color:#ffffff;"="">赵赛坡

无源晶振与有源晶振是电子系统中两种根本性的时钟元件,其核心区别在于是否内置振荡电路。晶振结构上的本质差异,直接决定了两者在应用场景、设计复杂度和成本上的不同。

RTC(实时时钟)电路广泛采用音叉型32.768kHz晶振作为时基源,但其频率稳定性对温度变化极为敏感。温度偏离常温基准(通常为25℃)时,频率会产生显著漂移,且偏离越远漂移越大。

有源晶振作为晶振的核心类别,凭借其内部集成振荡电路的独特设计,无需依赖外部电路即可独立工作,在电子设备中扮演着关键角色。本文将系统解析有源晶振的核心参数、电路设计及引脚接法,重点阐述其频率稳定度、老化率等关键指标,并结合实际电路图与引脚定义,帮助大家全面掌握有源晶振的应用要点,避免因接线错误导致器件失效。

晶振老化是影响其长期频率稳定性的核心因素,主要表现为输出频率随时间的缓慢漂移。无论是晶体谐振器还是晶体振荡器,在生产过程中均需经过针对性的防老化处理,但二者的工艺路径与耗时存在显著差异。

在现代汽车行业中,HUD平视显示系统正日益成为驾驶员的得力助手,为驾驶员提供实时导航、车辆信息和警示等功能,使驾驶更加安全和便捷。在HUD平视显示系统中,高精度的晶振是确保系统稳定运行的关键要素。YSX321SL是一款优质的3225无源晶振,拥有多项卓越特性,使其成为HUD平视显示系统的首选。



