发布时间:2024-03-5 阅读量:3034 来源: 综合网络 发布人: bebop
AI年度盛事英伟达GTC(GPU Technology Conference)大会于美西时间3月17日登场,市场估H200及B100将提前发表抢市。据了解,H200及次世代B100将分别采台积电4nm及3nm制程,H200将于第二季上市,B100采Chiplet设计架构传已下单投片。法人指出英伟达订单强强滚,台积电3、4nm产能几近满载,首季营运淡季不淡。
资料显示,NVIDIA H200 基于 NVIDIA Hopper 架构,与 H100 相互兼容,这意味着已经使用先前模型进行训练的人工智能公司将无需更改其服务器系统或软件即可使用新版本。
H200 是首款以 4.8 TB/s 速度提供 141 GB HBM3e 内存的 GPU,这几乎是 NVIDIA H100 Tensor Core GPU 容量的两倍。H200 还配备了高达 141GB 超大显存,与 H100 的 80GB 相比,容量几乎翻倍,并且带宽还增加了 2.4 倍。
这款新的 GPU 基于 H100 进行了升级,内存带宽提高了 1.4 倍,内存容量提高了 1.8 倍,提高了处理生成式 AI 任务的能力。该公司高性能计算和超大规模数据中心业务副总裁 Ian Buck 表示:「英伟达在硬件和软件上的创新正在缔造新型 AI 超算。」
英伟达在官方博客中表示:NVIDIA H200 Tensor Core GPU 具有改变游戏规则的性能和内存功能,可增强生成式 AI 和高性能计算 (HPC) 工作负载。作为首款采用 HBM3e 的 GPU,H200 借助更大更快的内存可加速生成式 AI 和大型语言模型 (LLM) 的运行,同时推进 HPC 工作负载的科学计算。
针对英伟达新世代晶片订单塞爆台积电先进制程一事,台积电表示,产能制程仍依照上次法说会所述内容,不再做说明。
英伟达日前强调,生成式AI及大型语言模型计算非常密集,需要多个GPU组成,然从客户购买到推论模型上线,需要几个季度的时间;换言之,今年看到的推论应用,是来自去年购买的GPU,意味着随着模型参数成长,GPU需求势必延续跟着扩大。
除GPU数量增加外,英伟达GPU效率也将在今年大幅提升,Blackwell系列的B100就是被市场视为下一世代英伟达GPU利器,除了是首款采台积电3nm打造外,更是第一款以Chiplet及CoWoS-L形式封装的英伟达产品,解决高耗电量与散热问题,单卡效率及电晶体密度,预估又将超车AMD首季推出的MI300系列。
半导体业者指出,台积电2023年即提前因应产能吃紧的现象,尤其针对先进封装CoWoS产能,除移机挪出龙潭厂空间外,竹南AP6也如火如荼启用;据供应链透露,原本今年下半年动工之铜锣厂,已规划提早于第二季进行,目标就是力拼2027年上半年,能够提供月产11万片12吋晶圆的3D Fabric量能。
台积电先进制程也持续满载,台积电2月产能利用率持续超过9成,AI需求不减。供应链表示,AI、HPC等应用一片晶圆能产出之晶片仅为消费性产品的四分之一,生产制造难度更高、更复杂;台积电能达到稳定量产,对晶片业者来说,非常重要。
此外,在H200转向新记忆体HBM,也将面临产能限制。H200到B100积极与云端服务供应商(CSP)进行新平台衔接,英伟达强调,数据中心功率密度是关键,多数CSP提前2~3年确保数据中心容量,必须提前规划。
除CSP业者外,较小型的语言模型开发商,因无法负担ASIC开案费用,多数将使用英伟达解决方案,积少成多下,也将成订单主力,台积电目前HPC/AI应用平台占营收比重达43%,已与智慧型手机齐平。


英特尔计划向人工智能芯片初创公司SambaNova追加投资1500万美元,该公司董事会主席由英特尔CEO陈立武担任。

据4月2日消息,台媒《工商时报》此前报道称联发科已开始下调在晶圆代工厂的4nm工艺投片量;而《电子时报》消息进一步指出,高通也已跟进采取类似减产措施。
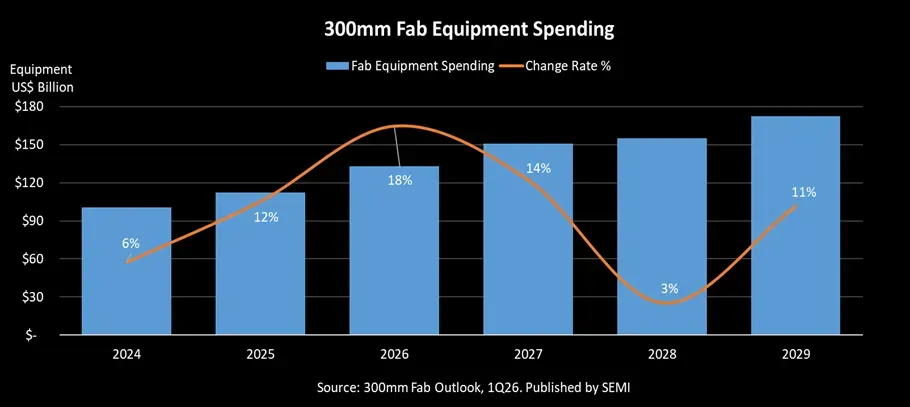
根据SEMI最新发布的《300mm晶圆厂展望》报告,预计全球300mm晶圆厂设备支出将在2026年实现18%的增长,达到1330亿美元,并将在2027年进一步增长14%,至1510亿美元。

FuriosaAI 的第二代 AI 推理芯片 RNGD 初始配备 48GB HBM3 内存,近期将升级至 72GB HBM3E

受全球智能手机需求走弱影响,供应链已转为防守状态。据供应链相关消息,由于手机市场前景不明朗,手机芯片(SoC)厂商已开始下调投片规模,其中联发科已在晶圆代工厂减少4nm制程芯片的投片量,反映出手机产业链景气度明显降温。



