发布时间:2025-04-29 阅读量:3243 来源: 我爱方案网 作者:
【导读】在AI算力爆发与云计算需求激增的2025年,数据中心面临高带宽、低时延、低成本的三重挑战。GIGALIGHT推出的400G QSFP-DD SR4至4×100G单波互连方案,以“单波长100G PAM4”技术为核心,突破传统并行架构的瓶颈,实现单端口带宽利用率提升300%、功耗降低20%,并减少75%的光电转换单元,为全球超大规模数据中心提供兼具弹性与经济效益的短距连接新范式。这一方案不仅解决了传统400G部署中光纤资源浪费、端口密度不足、TCO过高等痛点,更在NVIDIA GPU集群、云原生Spine-Leaf架构等场景中验证了其技术领先性。

方案优势与痛点解决
核心创新与优势
1. 高密度弹性架构
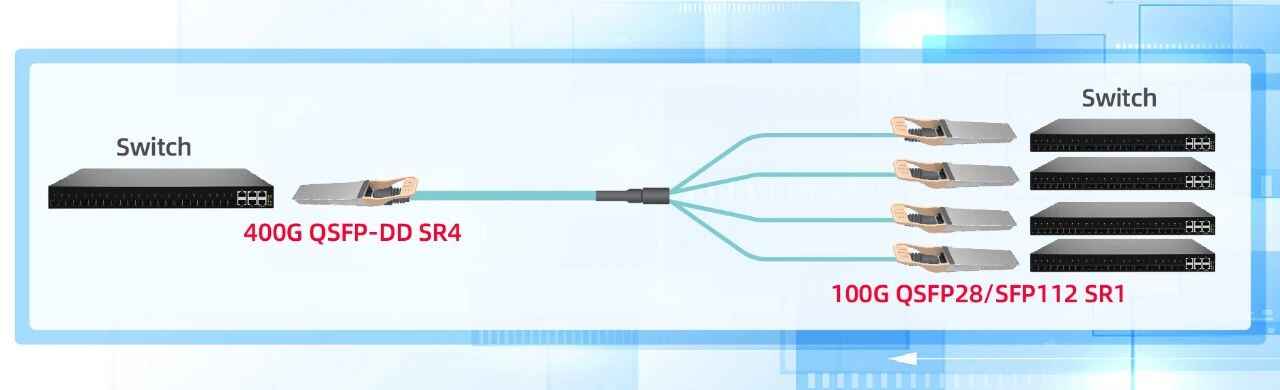
● 模块化设计:400G上行端口分支为4路独立100G链路,单端口利用率提升300%,节省交换机端口资源。
● 跨平台兼容:适配NVIDIA、Broadcom等主流交换芯片,无缝对接现有TOR架构。
2. 单波技术突破
● 单波长100G PAM4调制:在OM4多模光纤实现100米稳定传输,较传统方案减少50%光纤占用,功耗降低20%。
3. 经济性优化
● 成本削减:减少75%高速光电转换单元,光纤使用量降低至传统方案的25%。
● 快速部署:支持热插拔与即插即用,部署周期缩短60%。
行业痛点与解决方案对比

国际竞品对比与数据支撑
主流400G短距方案性能对比

数据来源:GIGALIGHT官网技术白皮书、FiberMall测试报告、行业调研
竞品案例分析
● Cisco QSFP-DD SR8:采用8通道50G PAM4,需16芯光纤,部署复杂且成本高,适用于交换机间互联,但在服务器连接场景中劣势明显。
● NVIDIA OSFP SR4:专为GPU集群设计,传输距离仅50米,需定制接口,限制现有基础设施兼容性。
典型应用场景与价值验证
1. AI/GPU集群互联
● 低时延(<85ns)支持千卡级GPU并行训练,数据传输效率提升40%。
2. 云数据中心Spine-Leaf架构
● 横向流量优化,核心层带宽压力降低35%,支持弹性扩展至10万台服务器集群。
3. 存储网络升级
无缝对接NVMe over Fabric协议,读写延迟降低至微秒级,加速实时数据分析。
在数据中心迈向400G+时代的关键节点,GIGALIGHT以单波技术革新与模块化弹性架构重新定义了短距互联的经济性与效率天花板。该方案不仅通过实测数据验证了其对标国际竞品的技术领先性(功耗降低20%、部署成本削减75%),更凭借全场景兼容能力,为AI算力集群、超大规模云数据中心提供了“一步到位”的平滑升级路径。随着单波100G PAM4技术的持续迭代,GIGALIGHT正加速推动全球开放光网络向**“一纤多业务、一网多代际”**的愿景演进,助力客户以更低TCO抢占智能算力时代的战略先机。未来,这场由光连接密度与能效比驱动的革命,或将成为数据中心互联赛道的终极胜负手。


磁电式编码器消除了易损的光学部件和复杂的绕组结构,其固态设计带来了更长的平均无故障时间(MTBF)与更低的生命周期维护成本。
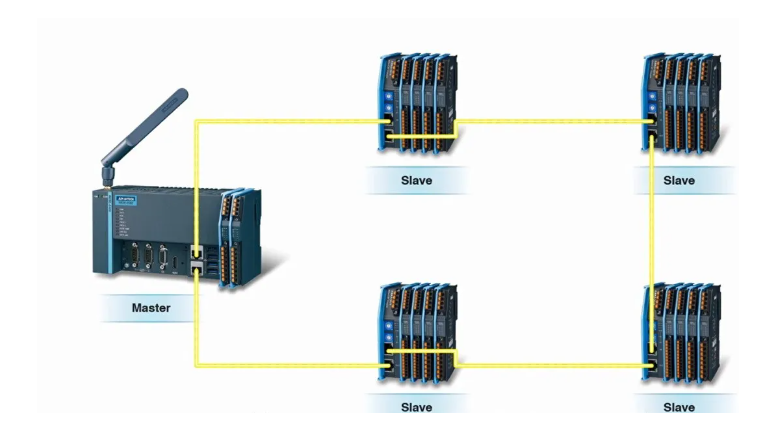
EtherCAT 网络可连接多达 65535 个设备,网络容量几乎没有限制,可以将模块化的 I/O 设备设计为每个 I/O 片都是一个独立的 EtherCAT 从站

先楫HPM5301秉承了先楫半导体一贯的高性能特性及架构,在性能上做到了极大的突破。

方案采用两相交错无桥图腾PFC拓扑,工作于CCM(连续导通模式),峰值效率>99%

今年1月发布的MYD-YT153MX-MINI开发板精准切入国产核心板中端市场,以极致性价比获得了良好的市场反响。



