发布时间:2026-04-2 阅读量:3070 来源: 发布人: suii
在边缘计算场景中,算力与实时性的平衡始终是技术演进的核心课题。近期,基于MYD-LR3576开发板与PCIe M.2接口的Hailo-8算力卡所展开的深度测试,获取了一系列实测数据,其结果有助于业界重新审视边缘AI在性能与效率上的实际边界。
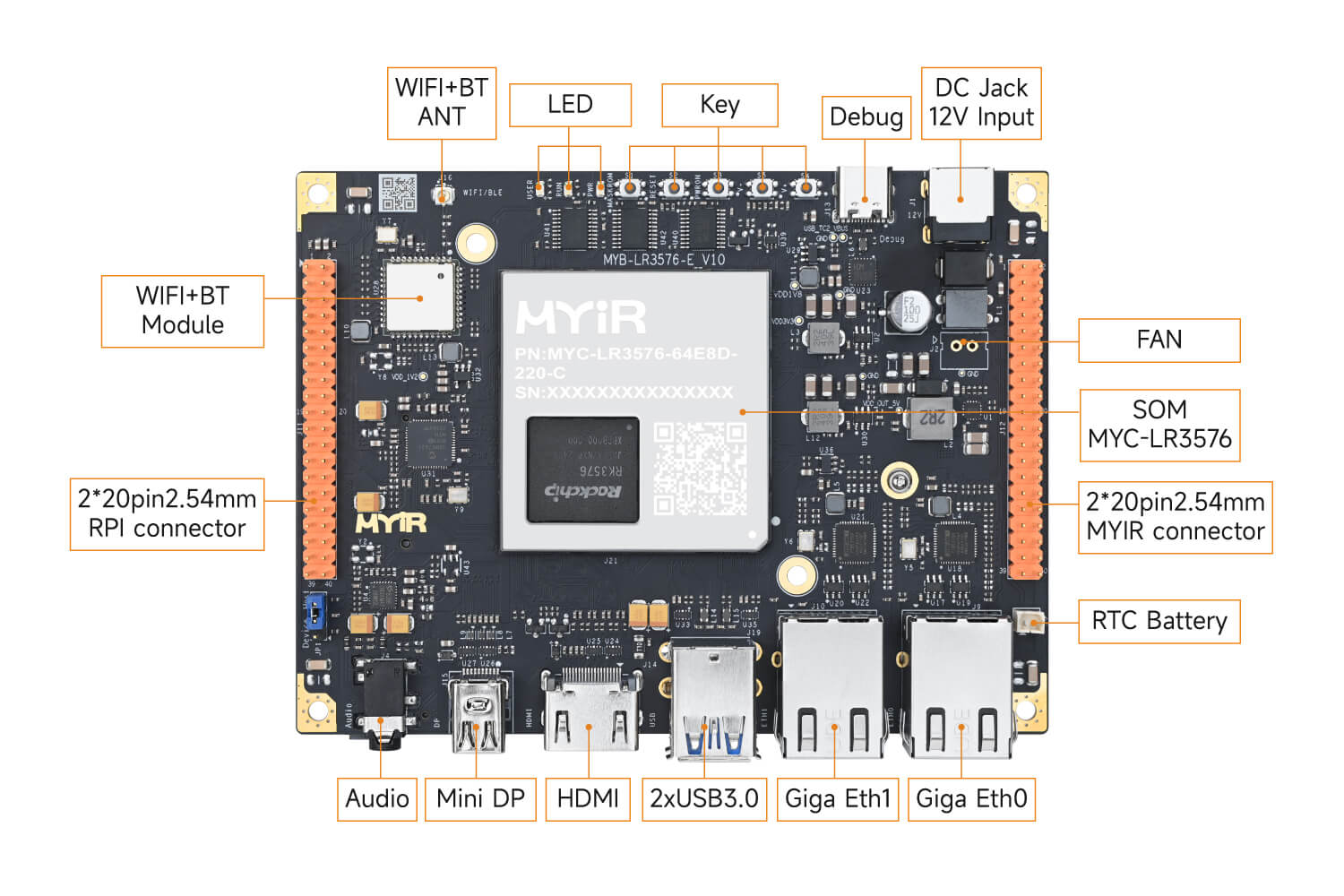
图:基于RK3576开发板
一、RK3576 的算力极限在哪里?
RK3576 内置 NPU 由 2 核组成,具备 6 TOPS 算力,在常规轻量级模型推理中表现不俗。但在实际项目中,我们通过多路并发测试发现,当 4 路 YOLOv5 模型同时推理时,NPU 负载率已超过 75%。一旦增加到第5路,整体延迟急剧飙升,系统响应明显劣化。
在单路推理场景下,YOLOv5(640×640)耗时约26ms,折算下来仅能稳定处理30fps的摄像头数据。
这意味着什么?
当摄像头升级到60fps 甚至 120fps 的高帧率场景时,单靠 RK3576 的 NPU 已经无法做到逐帧实时处理。要么丢帧,要么延迟不断累积——这在工业高速检测、智慧交通、机器人导航等对实时性要求严苛的应用中,是不可接受的。

二、Hailo-8算力卡介绍
Hailo-8 是一款专为边缘 AI 推理设计的专用加速器,拥有26TOPS算力,面向嵌入式设备和低功耗场景,提供高效、可扩展的 AI 计算能力。
为什么 Hailo-8 能在相同功耗下实现数倍于传统 NPU 的性能?答案不在算力数字,而在架构:
1. 数据流架构(Dataflow Architecture)
传统 NPU 像“工厂”从仓库(DDR)来回搬运数据,效率受限于搬运速度。而 Hailo-8 的数据流架构让数据在芯片内部“流水线式”流动,大幅减少对外部内存的依赖。简单说:算力不再是瓶颈,内存带宽才是——而 Hailo-8 绕开了这个瓶颈。
2. 无外部 DRAM 依赖
Hailo-8 不依赖外部大带宽内存,推理过程中几乎不与 CPU/NPU 争抢 DDR 资源。在多路视频并发场景下,这意味着系统不会因为“抢内存”而掉帧,整体稳定性大幅提升。
三、实测数据:让性能说话
在相同模型条件下(YOLOv5s):
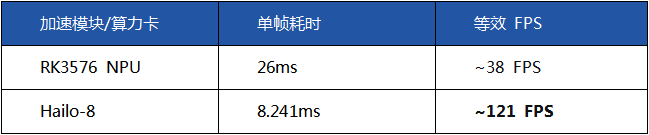
在更复杂模型(YOLOv8s)测试中,Hailo-8算力卡benchmark测试如下:

7 毫秒的推理延迟意味着:即使是120fps的高速摄像头,系统也能轻松应对,做到逐帧实时处理。
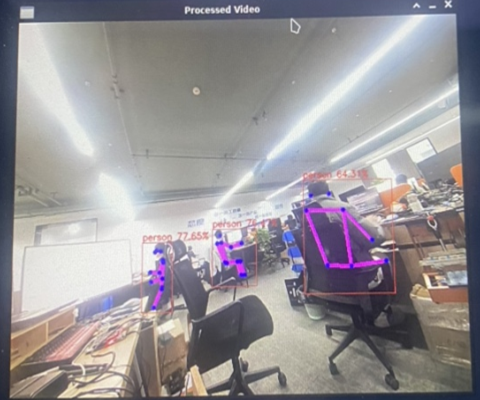
我们还运行了 Hailo-8 自带的摄像头实时推理示例,效果如下:

四、应用场景:当实时性成为刚需
这套方案能解决哪些实际问题?我们来看几个典型场景:
工业高速视觉检测:120fps 工业相机捕捉高速产线上的工件,Hailo-8 的 8ms 推理延迟确保缺陷被实时发现并剔除,避免漏检流入下一道工序。
智慧交通卡口:车辆高速通过时,系统需毫秒级完成检测+识别+跟踪。208 FPS 的吞吐能力让单节点可同时处理多模型,不丢车、不漏牌。
安防边缘节点:4 路以上 4K 视频同时分析,Hailo-8 的高吞吐让单节点覆盖范围翻倍,大幅降低每路视频的硬件成本。
五、总结:弹性算力,从容应对高帧率挑战
通过以上测试,我们可以清晰地看到:
· 引入 Hailo-8 算力卡后,YOLOv5 推理时间缩短至8ms,YOLOv8实测达到208 FPS 的吞吐量,不仅轻松覆盖 120fps 摄像头的全帧率推理,更预留了充足的算力余量。
· 弹性算力,按需选择:成本敏感项目可单独使用 RK3576;高帧率、低延迟场景只需增加 Hailo-8 模块,无需更换主控。
· 突破架构局限,实现真正实时:Hailo-8 的数据流架构将有效算力利用率提升至 80% 以上,配合 RK3576 的 PCIe 2.1 接口,让推理延迟从毫秒级压缩至微秒级。
· 为未来预留空间:算法快速迭代的今天,RK3576 + Hailo-8 的组合为未来两年的算法升级提供了充足的算力冗余,保护客户的硬件投资。



磁电式编码器消除了易损的光学部件和复杂的绕组结构,其固态设计带来了更长的平均无故障时间(MTBF)与更低的生命周期维护成本。
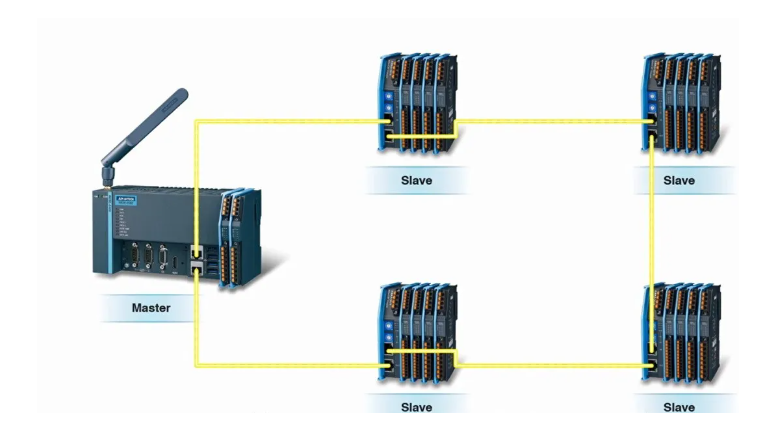
EtherCAT 网络可连接多达 65535 个设备,网络容量几乎没有限制,可以将模块化的 I/O 设备设计为每个 I/O 片都是一个独立的 EtherCAT 从站

先楫HPM5301秉承了先楫半导体一贯的高性能特性及架构,在性能上做到了极大的突破。

方案采用两相交错无桥图腾PFC拓扑,工作于CCM(连续导通模式),峰值效率>99%

今年1月发布的MYD-YT153MX-MINI开发板精准切入国产核心板中端市场,以极致性价比获得了良好的市场反响。



