【导读】论文对MELP编解码算法的原理进行了简要分析,讨论了如何在定点DSP芯片MS320VC5416上实现该算法,并研究了其关键技术,最后对测试结果进行了分析。
“好消息!2015年新年来临之际,我爱方案网准备了ST开发板、庆科WIFI模块开发套件以及智能硬件研发必备的精密样片,只需填写个人信息与开发计划即有机会获得。更多详情>>>>”
1 引言
1996年3月,美国政府数字语音处理协会(DDVPC)选择了2.4kbps混合激励线性预测(MELP)语音编码器作为窄带保密语音编码的产品以及各种应用的新标准由于MELP具有良好的音质、极低的码率,以及良好的抗误码特性,可以应用在IP PHONE、移动通信、卫星通信等领域,尤其在需要大量存储话音的场合和保密通信等方面,具有很好的发展前景。
编码算法有硬件实现和软件实现两种方式,软件实现灵活性强,但处理速度较慢,一般不能满足实时处理的要求。硬件实现分为专用法和通用法两种。通用法是基于通用数字信号处理器芯片实现编码算法的,它具有体积小、功耗低、运算速度快等优点,其灵活性主要表现在软件易于更改以及对各种算法的处理和复杂算法的实现上,非常适用于语音信号、视频信号等压缩处理。
MELP算法复杂度较高,因此实时实现必须借助于高性能的数字信号处理芯片。目前国内还没有用于研究声码器算法的专用芯片。因此,从功耗和性能多方面考虑,本文采用通用法实现MELP声码器算法,选择TI公司的TMS320VC5416 DSP芯片作为主处理器,完成声码器的主要功能。
2 MELP编解码算法
2.1 编码部分
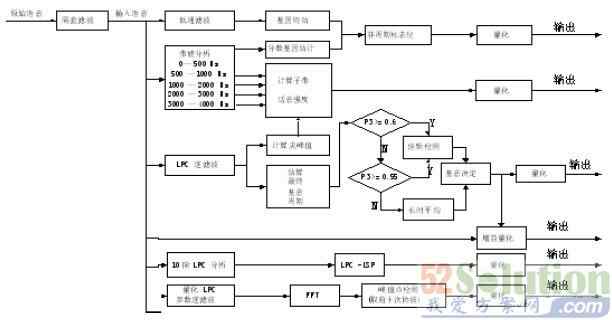
编码器基于线性预测分析合成技术,采样率为8kHz,以180采样值(22.5ms)为一帧进行编码,总体框图见图1。
输入的原始语音信号经过隔直滤波(即高通滤波),得到目标信号S(n)。再对目标信号作以下处理:①低通滤波后用归一化互相关法进行基音粗估,然后根据[0Hz,500Hz]子带信号围绕粗估基音估算分数基音;②带通分析,在5个子带计算话音强度,以决定各子带的清/浊音判决,其中[0Hz,500Hz]子带强度用于确定非周期标志位;③计算LPC和尖峰值,用L-D算法提取10个LP系数,然后乘以带宽扩展系数,使用得到的系数计算残差信号,对残差信号的160个抽样计算尖峰值;④使用截止频率为1kHz的6阶巴特沃兹滤波器低通滤波残差信号,结合上一子帧的基音和当前子帧的分数基因,搜索出最终基音周期;⑤使用一个基音自适应窗采用一帧两次的方法对增益进行量化;⑥LPC分析,并转换成线谱对LSP参数量化;⑦将量化后的LSP参数转换为LPC参数并进行逆滤波操作,残差信号补0至512点,对其进行512点FFT,利用频谱峰点检测算法找到前10次谐波对应的傅立叶系数输出。
图1 MELP编码器编码原理图
2.2 解码部分
解码器从信道接收到的数据中恢复出每帧的所有参数,经判断如果此帧是比较安静的语音帧,则增加对接触的两个子帧增益进行噪声衰减处理,同时改变噪声估计的值。所有合成的参数对其做基音同步内插处理,这些内插的参数包括基音周期、增益、LSF系数、颤动强度、量化的傅立叶幅度、用于产生混合激励信号的周期信号滤波器的系数和噪声滤波器系数、自适应增强滤波器的谱斜度系数。内插完成后,使用被子带滤波器滤波后的周期信号和噪声激励信号相加来产生混合激励信号。然后两个激励信号被分别滤波,并相加得到激励信号。合成混合激励信号后,信号经自适应谱增强滤波器处理,以改善共振峰的形状。随后,激励信号进行LPC合成得到合成语音。LPC合成用了一个直接形式的滤波器,其系数由插值后的LSP参数得到,合成的语音信号经增益调整和脉冲散布滤波后输出。总体框图见图2。
图2 MELP编码器解码原理图
3 TMS320VC5416简介
TMS320VC5416的总体系结构图如图4所示。其内部的高性能CPU拥有算术逻辑单元ALU、2个40位累加器ACCA和ACCB、40位桶行移位寄存器、乘累加单元以及寻址单元,算术逻辑单元包括1个40位的ALU,1个比较、选择和存储单元(CSSU)和1个指数编码器,具有高度的并行性。本文采用的TMS320VC5416芯片最大可寻址能力为192K字(包括64K字的程序空间、64K字的数据空间和64K字的I/O空间),扩展寻址模式下有256K字~8M字的扩展地址空间,并拥有一套高效灵活的指令集。其指令周期为6.25ns,执行速度最高可以达到160MIPS,完全可以满足实时处理的要求。
图3 TMS320VC5416总体系结构图
4 软件设计及其关键问题
软件设计包括编码流程和解码流程,编码流程图如图3所示。由于解码过程相对简单,故此处只给出编码流程图。
此软件流程设计完全按照MELP原理,在实际编程过程中需要注意以下几个关键问题。
图4 MELP编码流程图
⑴存储器分配问题
由于TMS320VC5416采用双总线结构,提供了许多多功能指令,在实际实现时要充分考虑到这些特点,尽量用多功能指令,并且合理分配使用各个寄存器和指针。例如:MAC指令可以在一个指令周期内完成乘加操作,还可以结合寄存器的合理安排实现连续乘加,而不需要缓存中间数据,从而大大提高了运算效率。另外,要充分利用TMS320VC5416提供的专用的硬件结构、寻址方式及特殊指令。如:环形存储器寻址方式、双操作数寻址方式、EXP指令和NORM指令、舍入操作等,恰当使用这些方式和指令可以大大提高软件效率。
⑵ 数的定标
TMS320VC5416采用定点数进行数值运算,其操作数一般采用整型数表示。但它的指令支持小数模式和整数模式两种运算模式。对DSP而言,参与数值运算的数就是16位的整型数。在多数情况下,数学运算过程中的数不一定都是整数,这就需要程序员来确定小数点的位置,即数的定标。TMS320VC5416中数的定标有两种表示法:Q表示法和S表示法。在此软件中用Q表示法表示。
在程序中需要经常判断运算结果是否溢出。TMS320VC5416芯片本身设有溢出保护功能,溢出的处理是通过设置芯片中PMST寄存器的OVM位自动执行的。可以在程序的开始就设置溢出功能有效,一旦出现溢出异常,则累加器ACC的结果置为最大的饱和值(上溢位7FFFH,下溢位8001H),从而达到防止溢出引起精度严重恶化的目的。
⑶防止流水线冲突
流水线是TMS320VC5416最具特色的部分,它大大的提高了TMS320VC5416的性能,但当DSP资源同时被不在同一流水线阶段的指令使用,或在存取某些寄存器时容易引起流水线冲突。编译时会编译器将自动插入一个或几个空操作,从而增加了所需的计算量,降低了软件效率,因此软件设计开发中需要避免流水线冲突。
5 测试结果
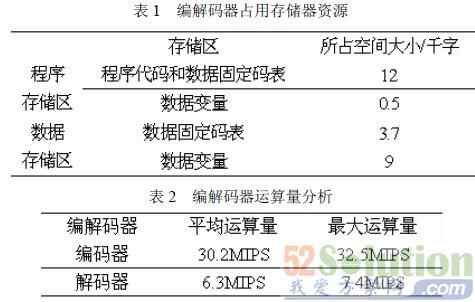
目前该编解码器已通过MELP的全部测试矢量验证。系统实时实现编解码时,经过非正式的主观测试结果表明,MELP算法的MOS分在3.3左右,其清晰度、自然度和抗噪声性能明显优于传统LPC算法。表1和2分别给出了在定点DSP芯片TMS320VC5416上实时实现MELP算法的编解码器所需的存储量和计算量。
从表1可见,程序和数据存储区总存储量共25.2K字,由于TMS320VC5416内部RAM的大小为128K字,因此,程序boot时,可以一次将所有程序和数据直接搬移到芯片内部RAM里运行。表2显示了对该声码器所用资源的统计结果。在全双工时,最大运算量为39.9MIPS,完成满足实时实现的要求。
以上分析结果显示,单片TMS320VC5416芯片最多可实现4路语音编解码,片上剩余的资源还可以实现其它附加功能。
创新点:本文介绍了混合激励线性预测(MELP)声码器算法,简要分析了该算法的编解码原理。同时,本文选用TI公司的TMS320VC5416 DSP芯片进行了实时实现,指出了在软件实现中需要注意的关键问题。经非正式主观测试结果表明,该算法自然度、清晰度和抗噪声性能明显优于传统LPC算法,适用于短波窄带数字保密通信、无线通信等需要低速率的语音编码场合,具有广阔的应用前景。
相关文章
基于DSP的谐波控制器设计方案
DSP技术在变电站的综合自动化系统设计方案
DSP/BIOS的智能PLC执行系统的设计方案