发布时间:2021-09-14 阅读量:1461 来源: 我爱方案网 作者: 我爱方案网整理
数据规模的快速增长给大数据分析处理带来了巨大的挑战,尤其是在通信行业,数据越发呈现出无限性、突发性和实时性等特征[3],传统的基于MapReduce的批处理模式难以满足数据实时性的要求,而能否在第一时间获得数据所蕴含的信息决定了数据的价值。因此,流式处理技术成为大数据技术研究的新热点[4]。流式处理能够针对数据的变化进行实时处理,能够在秒级获得处理结果,特别适合一些对时效性要求很高的场景。
对DPI数据进行实时的采集及处理,提出一种基于流式计算的DPI数据处理方案,能够将获得DPI数据实时信息的时延降低到分钟级,甚至秒级,实现对电信用户上网信息的实时处理、监测及分类汇总,为之后进行的大数据应用提供了良好基础。
流式计算架构对比
流式计算对系统的容错、时延、可扩展及可靠性能力提出了很高的要求,当前有许多流式计算框架(如Spark streaming[10]、Storm[11]、Kafka Stream[12]、Flink[13]和PipelineDB[14]等)已经广泛应用于各行各业,并且还在不断迭代发展,适用的场景也各不相同。
架构对比
上文提到的5种流式处理框架对比如表1所示:
表1 流式框架对比

Storm的特点是成熟,是流式处理框架实际上的标准,模型、编程难度都比较复杂,框架采用循环处理数据,对系统资源,尤其是CPU资源消耗很大,当任务空闲时,需要sleep程序,减少对资源的消耗。Spark Streaming兼顾了批处理以及流式处理,并且有Spark的强大支持,发展潜力大,但与Kafka的接口平滑性不够。Kafka Stream是Kafka的一个开发库,具有入门、编程、部署运维简单的特点,并且不需要部署额外的组件,但对于多维度的统计来说,需要基于不同topic来做分区,编程模型复杂。Flink跟Spark Streaming很像,不同的是Flink把所有任务当成流来处理,在迭代计算、内存管理方面比Spark Streaming稍强,缺点是社区活跃度不高,还不够成熟;PipelineDB是一个流式计算数据库,能执行简单的流式计算任务,优势是基本不需要开发,只要熟悉SQL操作均可以轻松使用,但对于集群计算,需要商业上的支持。
DPI数据处理方案
基于实际任务需求以及上文流式框架的对比,由于Kafka Stream编程难度小,不需要另外安装软件,与Kafka等组件无缝连接,比较稳定,并且各种性能均比较优秀,因此本文选择了Kafka Stream作为流式处理的核心组件。
4.1宽带DPI处理
为了完成宽带DPI数据的实时抓包、资料填补、清洗、转换及并入库等工作,应用了上述DPI数据处理方案。具体项目方案如图5所示:
图6 4G DPI实时统计方案图
数据源是gzip压缩文件,因为flume原生不支持.gz或.tar.gz文件格式,所以修改了Flume底层代码,实现对压缩文件的处理,省去了解压时间。Flume采集文件时以用户手机号码作为分区的key,将同一号码的数据分到同一分区,便于去重。通过Kafka集群管理工具,Kafka Manager[17]可以很好地监测Kafka集群的状态。Kafka集群生产者如图7所示:

图7 Kafka集群生产者
Kafka Stream消费4GDPI的数据,并行处理。在程序里设置不同的计数器,所有数据都经过这些计数器处理,为了解决去重问题,引入了布隆过滤,虽然有一定的误判率,但是还是能比较好的完成去重,同时保证系统的性能。同样消费者也可以通过Kafka Manager进行管理,可以直观观察到消费者的落后程度。
为了满足不同的输出要求,程序设置了三种输出供选择。粒度为天的数据将会写到MySQL作为备份,针对热点区域的监控数据将会输出到Redis,同时,为了方便管理以及数据呈现,还采用了ELK框架(ElasticSearch+Logstash+Kibana),将所有数据传到Kibana做前端展示。Kibana界面如图8所示:

Kibana界面
5 实践及分析
5.1 部署实践
上述两个系统均已应用在实际的生产中,均有不错的表现,能够满足任务需求,并且已经稳定运行。
宽带DPI处理项目有2台采集机、1台AAA服务器及5台Kafka机器。采集机每台每秒产生115 MB数据,两台1.8 G流量。采集机写Kafka 33万条/秒,Kafka Stream写Kafka 22万条/秒,清洗率(清洗工作把诸如图片、视频及js请求等与业务无关的DPI信息去掉)为33%。Kafka Stream落后处理稳定在500万数据,延迟处理在15 s之内,Flume写HDFS落后保持在100万左右,5 s内的延迟。
存在的问题
在4G DPI实时统计项目开发过程中,随着项目的需求越来越多,后面增加了对域名和CGI的去重,而且同一域名或者CGI不在同一Kafka分区,导致结果有偏差。为了解决这一问题,程序设计了二次去重,第一次去重的结果把CGI或者域名作为key输出到Kafka集群,再做了一次去重工作,导致延迟时间变大和系统维护变复杂。
由于宽带DPI处理中不涉及去重,只是数据过滤和数据转换,因此Kafka Stream是非常适合的。但在涉及分区和去重的4G DPI实时统计项目中,应当采用Storm作为流式处理框架。在Storm中,数据从一个bolt流到另外一个bolt,这样数据可以在一个bolt中按手机号码分区,在另外一个bolt中又可以按CGI或者域名分区,可以避免二次去重问题,降低编程模型复杂度。
程序设计之初,应根据应用场景需求选择合适的技术框架。如果项目基础结构中涉及Spark,那Spark Streaming是不错的选择;如果像4G DPI实时统计项目一样需要数据转移或者去重,那么Storm是首选;如果是简单的数据清洗和转换处理,那么Kafka Stream是不错的选择。对于简单小规模的实时统计,PipeLineDB足以胜任。
推荐阅读:

在任何数字电子系统中,时钟信号都扮演着“心脏起搏器”的角色。

RTC晶振与普通32.768kHz晶振的PCB设计要点基本一致,其核心均在于通过优化布线以降低杂散电容、确保频率精度,并依托合理的布局规划最大限度屏蔽来自板上其他信号源的电磁干扰。

按晶振的功能和实现技术的不同,分为温度补偿晶振(TCXO)、压控晶振(VCXO)、恒温晶振(OCXO)。
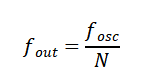
为了在性能与功耗之间取得最佳平衡,需要根据具体应用场景,对基准时钟进行相应的分频、倍频或转换处理,从而为各模块提供适宜的时钟信号。此时,分频技术就成为连接晶振基准频率与系统需求的关键,通过数字电路将晶振原始频率按固定比例降低,输出符合要求的低频时钟信号。

RTC芯片是一种专门用于精准计时、掉电续时的专用集成电路,其核心功能是提供精准、稳定的时间信息(包括秒、分、时、日、月、周、年),并能在主电源断电后依靠备用电池继续保持计时,从而确保时间持续不间断。



