发布时间:2023-05-10 阅读量:8050 来源: 面包板社区 发布人: Doris
GPU的起源确实是基于图形处理的需求。早期还没有专门GPU时,我们打游戏所有的逻辑处理都放在CPU执行,CPU的处理能力越来越强,但经不
住游戏画面增长的更快,这就对图形处理提出了更高的要求。
而图形处理的本质其实就是光影的计算,以下图为例,在屏幕上画一个圆非常简单。


游戏画面也是这样的逻辑,一个画面优质的游戏一定是有丰富的光影效果,而光影效果的本质其实就是在虚拟的3维空间里,模拟光的照射。屏幕中的画面其实就是特定角度下,由计算机计算出的,你应该看到的光影效果。

需要特别注意的是,游戏中你会不停的移动,也就是所有光影的效果都需要实时的计算出来。假设屏幕分辨率为1920*1080,即2073600(207.36万)个像素,游戏中每个像素都需要根据光影参数来计算显示的颜色和明暗。假设一个常见的Inter I5 CPU主频为3.2GHz,即最多每秒可做32亿次运算。但这里的一次运算只是做了一次简单的二进制加减法或数据读取,一个像素的光影计算我们可以假设需要100次运算,即CPU一秒约处理3200万次像素运算,大概15张图片,用专业点的说法,这个游戏流畅度大概是每秒15帧的样子。
一个典型的显卡GTX1060,主频是1.5GHz大概是Inter I5一半左右,但是它具备1280个计算核心。每个计算核心每秒可做15亿次运算,1280个核心每秒就是19200亿次运算,那一秒可以处理192亿次像素计算,大概925张图片,是CPU计算能力的61倍!但GPU的特性只能应用于图形计算这种可以并行的任务,若是做普通的串行任务其速度远远不如CPU。




作者:布兰姥爷
来源:面包板社区
https://mbb.eet-china.com/blog/3887969-441194.html
本文已获授权

在任何数字电子系统中,时钟信号都扮演着“心脏起搏器”的角色。

RTC晶振与普通32.768kHz晶振的PCB设计要点基本一致,其核心均在于通过优化布线以降低杂散电容、确保频率精度,并依托合理的布局规划最大限度屏蔽来自板上其他信号源的电磁干扰。

按晶振的功能和实现技术的不同,分为温度补偿晶振(TCXO)、压控晶振(VCXO)、恒温晶振(OCXO)。
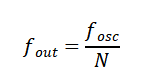
为了在性能与功耗之间取得最佳平衡,需要根据具体应用场景,对基准时钟进行相应的分频、倍频或转换处理,从而为各模块提供适宜的时钟信号。此时,分频技术就成为连接晶振基准频率与系统需求的关键,通过数字电路将晶振原始频率按固定比例降低,输出符合要求的低频时钟信号。

RTC芯片是一种专门用于精准计时、掉电续时的专用集成电路,其核心功能是提供精准、稳定的时间信息(包括秒、分、时、日、月、周、年),并能在主电源断电后依靠备用电池继续保持计时,从而确保时间持续不间断。



